
Using openCV and NLTK to Make Speech Synthesis Animation
The project of this article is hosted at http://github.com/kazenotenshi/NLPAnimation.
All the mouth images where found at http://www.garycmartin.com/mouth_shapes.html.
The Beginning
Hello, and if you’re here after a long time, so sorry for the long delay. After I came back from Japan I’ve been working a lot and had few time to continue updating this blog. Today, I’ll discuss and show some code of a prototype ( that is not something really fancy =) ) of an exercise to do some speech synthesis with animations of text files.
Let’s talk! The main idea is shown below:
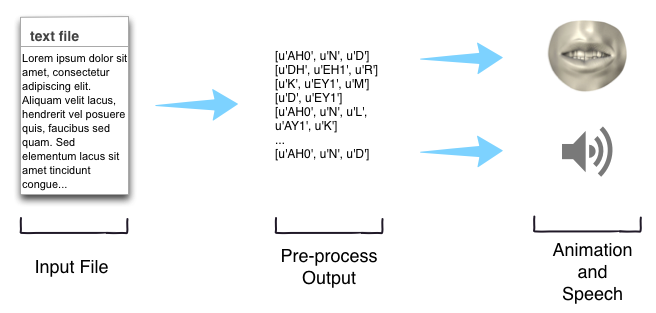
The main ideia is to transform text files into animations with mouth visualization and speech synthesis. To do so, my goal is to pre-process this file and transfer it into phonemes and then use it to generate a synced speech synthesis and image animation. Let’s take a look at how to do it.
Coding
The main files of the project are phonemes.py and imageprototype.py. The other ones where just small tests that I had conducted during the development just to verify some assumptions.
The file phonemes.py is more like a “.h” file to store the image library and the phonemes correspondence to these images that is gonna be really useful during the pre-processing phase. Each word will be translated to a list of phonemes ( e.g: NATURAL = [N ,AE1,CH,ER0,AH0,L] ) and that the global list of phonemes will have an image associated to it. Refer to NLTK Doc ( here ) about how these phonemes work. Along with the phoneme information, NLTK provides some intonation information of every word, it will be useful later. The file phonemes.py has two main structures: mouths and PhonemesToMouth. The file is implemented as shown below:
import cv2
import numpy as np
import os
import time
import sys
import nltk
## Importing all the mouth images
mouths = {}
for i in os.listdir("./mouths"):
if i.endswith(".jpg"):
print i
img = cv2.imread("./mouths" + "/" + i, 0)
mouths["" + i] = img
continue
#print mouths
#Creating the Dictionary between phonemes and mouths
PhonemeToMouth={'AA':'blair_o.jpg',
'AH':'blair_c_d_g_k_n_r_s_th_y_z.jpg',
'AW':'blair_c_d_g_k_n_r_s_th_y_z.jpg',
'AE':'blair_a_i.jpg',
'AO':'blair_o.jpg',
'AY':'blair_a_i.jpg',
'B':'blair_m_b_p.jpg',
'CH':'blair_c_d_g_k_n_r_s_th_y_z.jpg',
'DH':'blair_c_d_g_k_n_r_s_th_y_z.jpg',
'D':'blair_c_d_g_k_n_r_s_th_y_z.jpg',
'EH':'blair_e.jpg',
'EY':'blair_a_i.jpg',
'ER':'blair_u.jpg',
'F':'blair_f_v_d_th.jpg',
'G':'blair_c_d_g_k_n_r_s_th_y_z.jpg',
'HH':'blair_c_d_g_k_n_r_s_th_y_z.jpg',
'IY':'blair_e.jpg',
'IH':'blair_a_i.jpg',
'JH':'blair_c_d_g_k_n_r_s_th_y_z.jpg',
'K':'blair_c_d_g_k_n_r_s_th_y_z.jpg',
'L':'blair_l_d_th.jpg',
'M':'blair_m_b_p.jpg',
'NG':'blair_c_d_g_k_n_r_s_th_y_z.jpg',
'N':'blair_c_d_g_k_n_r_s_th_y_z.jpg',
'OY':'blair_a_i.jpg',
'OW':'blair_o.jpg',
'P':'blair_m_b_p.jpg',
'T':'blair_l_d_th.jpg',
'R':'blair_c_d_g_k_n_r_s_th_y_z.jpg',
'SH':'blair_c_d_g_k_n_r_s_th_y_z.jpg',
'S':'blair_c_d_g_k_n_r_s_th_y_z.jpg',
'TH':'blair_f_v_d_th.jpg',
'UH':'blair_c_d_g_k_n_r_s_th_y_z.jpg',
'UW':'blair_u.jpg',
'W':'blair_w_q.jpg',
'V':'blair_f_v_d_th.jpg',
'Y':'blair_c_d_g_k_n_r_s_th_y_z.jpg',
'ZH':'blair_c_d_g_k_n_r_s_th_y_z.jpg',
'Z':'blair_c_d_g_k_n_r_s_th_y_z.jpg'}Now, let’s move to the next part. A sample text is written at sample.txt file. The first thing is to translate this file to a [word,phoneme] list. To do it, the program has to open the file, split the string into words using a tokenizer and find all the file correspondences in the phoneme dictionary. The code snippet bellow shows how to open the file, separate it into words, and find the phoneme correspondence to each word in the phoneme dictionary provided by NTLK.
file_content = open("sample.txt").read()
tokens = nltk.word_tokenize(file_content)
print tokens
entries = nltk.corpus.cmudict.entries()
print len(entries)
start_time = time.time()
TextToSpeech = []
for token in tokens:
for entry in entries:
if token.lower() == entry[0]:
TextToSpeech.append(entry)
breakA disclaimer: this is not the best optimized way to find words in a big list. Actually, it is really slow right now. For proof of concept purposes it just works. Still, I have some ideias to improve this part, I’ll try some stuff and probably put the results here later.
The TextToSpeech variable will hold something like:
[(u'and', [u'AH0', u'N', u'D']), (u'there', [u'DH', u'EH1', u'R']), ... ]Now, for every phoneme of every word, the phoneme time has to be inferred, and the proper image has to be shown during the speech. Here comes a harder part. I have researched many different libraries to do the speaking part. And none of then provided me a truly reliable callback to know the time for each word. The one I decided to use was the OSX’s NSSpeechSynthetizer, which is used by pyttsx library. Pyttsx is a python biding for Speech Synthesis in many different OS.
The hard coded part of this tutorial was to infer what is a normal phoneme, long phoneme and small phoneme. For each word, the program iterates over the list of phonemes and applies the corresponding times to each phoneme before the speech and visual processing. If the phoneme has a number 1 on it, it is a long phoneme, if it has a 0 it is a small one. Take a look at the code below:
timePerPhoneme = 0.15
longPhonemeBonus = 0.05
smallPhonemeBonus = -0.05
## For each mouth you should put a refering mouth to show
## do the double check
for word in TextToSpeech:
# Get the right list of mouths
timeForAWord = 0.0
timeOfThisPhoneme = 0.0
MouthsToShow = []
for ph in word[1]:
for key, value in phonemes.PhonemeToMouth.items():
if '1' in ph:
timeForAWord += timePerPhoneme + longPhonemeBonus
timeOfThisPhoneme = timePerPhoneme + longPhonemeBonus
elif '0' in ph:
timeForAWord += timePerPhoneme + smallPhonemeBonus
timeOfThisPhoneme = timePerPhoneme + smallPhonemeBonus
else:
timeForAWord += timePerPhoneme
timeOfThisPhoneme = timePerPhoneme
if key in ph:
MouthsToShow.append((value, timeOfThisPhoneme))Why do I hold both phoneme and word time? Because the phonemes time are used for the mouths independently, and the word time is used by the speech synthesis.
During speech, a main problem is that the call holds the program until all the speaking is done. Since the main ideia is to speech and visualization at the same time, a multi-threading approach must be done. Each time I need to speak a word, I’ll call a function from another thread to avoid interruptions and put a wait time, so the speaking is not cut in the middle. Look at the code below:
# called by each thread
def speak_word(word, waittime):
nssp = NSSpeechSynthesizer
ve = nssp.alloc().init()
ve.setVoice_("com.apple.speech.synthesis.voice.Alex")
ve.startSpeakingString_(word)
time.sleep(waittime)
return
# Call co-routine to speak
try:
t = thread.start_new_thread(speak_word, (word[0], timeForAWord ) )
except:
print "Error: unable to start thread for audio =/"Finally, the program uses the OpenCV to show the images of the mouths using the same time information collected before and the dictionary that maps mouths to phonemes. This part is shown below:
#Show Mouths
for mouth in MouthsToShow:
img = phonemes.mouths[mouth[0]]
cv2.imshow('window', img)
cv2.waitKey(1)
time.sleep(mouth[1])The complete imageprototype.py code is:
import cv2
import numpy as np
import os
import time
import sys
import nltk
import phonemes
import thread
import time
from AppKit import NSSpeechSynthesizer
#Defines
timePerPhoneme = 0.15
longPhonemeBonus = 0.05
smallPhonemeBonus = -0.05
# called by each thread
def speak_word(word, waittime):
nssp = NSSpeechSynthesizer
ve = nssp.alloc().init()
ve.setVoice_("com.apple.speech.synthesis.voice.Alex")
ve.startSpeakingString_(word)
time.sleep(waittime)
return
file_content = open("sample.txt").read()
tokens = nltk.word_tokenize(file_content)
entries = nltk.corpus.cmudict.entries()
start_time = time.time()
TextToSpeech = []
for token in tokens:
for entry in entries:
if token.lower() == entry[0]:
TextToSpeech.append(entry)
break
end_time = time.time()
## For each mouth you should put a refering mouth to show
## do the double check
for word in TextToSpeech:
# Get the right list of mouths
timeForAWord = 0.0
timeOfThisPhoneme = 0.0
MouthsToShow = []
for ph in word[1]:
for key, value in phonemes.PhonemeToMouth.items():
if '1' in ph:
timeForAWord += timePerPhoneme + longPhonemeBonus
timeOfThisPhoneme = timePerPhoneme + longPhonemeBonus
elif '0' in ph:
timeForAWord += timePerPhoneme + smallPhonemeBonus
timeOfThisPhoneme = timePerPhoneme + smallPhonemeBonus
else:
timeForAWord += timePerPhoneme
timeOfThisPhoneme = timePerPhoneme
if key in ph:
MouthsToShow.append((value, timeOfThisPhoneme))
# Call co-routine to speak
try:
t = thread.start_new_thread(speak_word, (word[0], timeForAWord ) )
except:
print "Error: unable to start thread for audio =/"
#Show Mouths
for mouth in MouthsToShow:
img = phonemes.mouths[mouth[0]]
cv2.imshow('window', img)
cv2.waitKey(1)
time.sleep(mouth[1])Discussion
Although it is pretty easy to do this kind of coding using some existing python bindings, it seems to be a little inefficient at start. I put a small paragraph to pre-process and it takes about 2 minutes. The main reason is the phoneme match part. Since the library just gives the whole dictionary it is really painful to iterate over some thousands of words to find the one you want. Some improvements can be done at this part of the code.
Also, all the speech libraries I have looked does not provide a true API to easily do the syncing. In the example I had to guess the phonemes times and use it along with the mouth visualization. Sometimes I get awful animations, totally unsync. I haven’t had time to investigate these libraries deeply, but it seems that if I want to have this level of detail, I’ll have to make my own. Besides all that, NLTK is a great way to process words into phonemes and OpenCV is really useful when dealing with images.
Thanks for reading, and I appreciate any feedback. See ya.